Technology
The Efficiency Heresy: Can India Build AI Without Burning Billions?
Karan Kamble
Feb 17, 2026, 10:01 AM | Updated 12:15 AM IST

In June 2023, Sam Altman visited India on a global tour celebrating OpenAI's explosive success. At an event organised by The Economic Times in Delhi, venture capitalist Rajan Anandan posed what seemed like a reasonable question: could a small, smart team of Indian engineers with $10 million build something substantial in artificial intelligence (AI)?
Altman's response was blunt. "It's totally hopeless to compete with us on training foundation models. You shouldn't try," he said. "And it's your job to try anyway. I think it is pretty hopeless."
The comments sparked immediate backlash. Tech Mahindra chief executive C P Gurnani tweeted "Challenge accepted." Minister of State for Information Technology (IT) Rajeev Chandrasekhar said Altman was "certainly not going to be the last word on what India's aspirations for AI are going to be." The controversy dominated Indian tech discourse for weeks.
Eighteen months later, in January 2025, a Chinese company called DeepSeek released an AI model that matched GPT-4's capabilities. Strikingly, its final training run cost approximately $6 million using 2,000 "GPUs," short for graphics processing units — a fraction of what OpenAI spent, though the full picture was more complicated. Altman's dismissive comments resurfaced across social media. "This is pretty hilarious in retrospect," noted entrepreneur Arnaud Bertrand, sharing the original clip.
But the real lesson of DeepSeek was not that Altman was wrong about India specifically. It was that he was wrong about something more fundamental: the assumption that building frontier AI requires billions of dollars in compute. DeepSeek proved that algorithmic efficiency could substitute for raw computational power to a remarkable degree.
This is a debate that has been simmering in the machine learning community for years, not very visible to the public but surely with consequences for the technological future of nations, including India’s.
On one side: the scaling paradigm, which holds that throwing more compute at AI models is the reliable path to better performance.
On the other: an older tradition that values algorithmic elegance and efficiency — or, simply, doing more with less.
This debate is important for India, not by choice but by circumstance. It cannot match American or Chinese spending on AI infrastructure. It faces export restrictions on advanced chips. Its AI strategy must therefore answer a question the wealthiest nations can ignore: is there a path to AI capability that does not require brute-force scaling?
A distinguished machine learning researcher believes there is. And he has been arguing for it for some years now.
The Voice in the Wilderness
M Vidyasagar is a Fellow of the Royal Society, former Executive Vice President of Tata Consultancy Services (TCS), and one of India's most accomplished control theorists. He has watched the field to which he has contributed immensely undergo a change he considers troubling.
“Five years ago, if I published an algorithm that took two hours to solve benchmark problem, and then you published your own algorithm that took only one hour, then the community would say that your algorithm is definitely better," he recalls.
"Now, nobody is even bothered about such a thing."
The shift goes beyond methodology. Vidyasagar argues that much AI research has abandoned basic scientific standards. Papers claim fantastic results on proprietary code that nobody can verify. The fundamental axiom of science — reproducibility — is routinely ignored. "Many of these big companies, they say, well, my code is proprietary. Don't you believe me?" he says. "No, we don't — that's not science."
His critique extends to India's strategy specifically.
"India has not got the resources to spend on a trillion-parameter model," he states bluntly. "I have always been advocating for fine-tuning existing networks. Creating a network ab initio requires huge resources. We're not going to be able to create that. So fine-tuning is the way to go."
This is pragmatism, he insists — and recent events have vindicated it.
The Gospel According to Scale
To understand how AI came to abandon efficiency — though some might argue it's not abandoned but merely deprioritised or pushed down the AI workflow — one might read a single essay that has perhaps reshaped the field's entire philosophy.
In March 2019, Richard Sutton, a legendary figure in AI research, published "The Bitter Lesson" on his personal website. In fewer than a thousand words, he made an argument that would become gospel in Silicon Valley's AI labs: clever algorithms lose to brute computational force. Apparently every time.
Sutton traced this pattern across decades. In chess, the system that defeated Kasparov relied not on encoded grandmaster knowledge but on massive search.
In Go, AlphaGo triumphed through self-play, rendering decades of human expertise encoding irrelevant.
In speech recognition, statistical methods beat linguistic theory.
The lesson was "bitter" because it trumped human ingenuity — researchers wanted their cleverness to matter, but empirical evidence kept suggesting otherwise.
This philosophy found mathematical foundation in "scaling laws." Beginning around 2020, researchers at OpenAI, DeepMind, and Anthropic showed that model performance improves predictably as you increase parameters, data, and compute. The relationship followed smooth power-law curves. More meant better, reliably.
The implications were profound. Once improvement looked like a power curve rather than conceptual breakthroughs, research strategy shifted from "find the next algorithm" to "raise more capital and scale the cluster." Intelligence appeared to be an engineering problem solvable with enough resources. The reality was more nuanced — Meta's compute rivalled OpenAI's yet its models lagged, suggesting algorithmic innovation still mattered — but the perception held, and shaped investment accordingly.
"The way this works is, like what Elon Musk did — he decided to buy 100,000 GPUs from Nvidia," Vidyasagar observes. "Now he can afford that. But nobody ever stops to ask: do we really need 100,000 GPUs? Can we not get the same thing with fewer?"
The question, once central to the field, had become almost heretical.
DeepSeek showed decisively that you can get comparable results with far less — but few have drawn the correct conclusions. Companies like Prime Intellect have demonstrated that post-processing pre-trained models can achieve similar performance with as few as 512 GPUs. Still significant, but orders of magnitude smaller than what frontier labs deploy.
The Incentive Structure
The abandonment of efficiency was driven by a constellation of incentives all pointing in the same direction.
Academic publication systems reward state-of-the-art results on benchmarks. A paper achieving 2 per cent higher accuracy gets accepted at top conferences; a paper achieving the same or slightly worse accuracy but with half the compute struggles for attention.
Investment incentives amplified the bias — "bigger model, better benchmarks" is a better story for venture capitalists.
Nvidia's roadmap incentivises compute growth; the company's stock price depends on selling more GPUs, not fewer.
And the arms race mentality among OpenAI, Anthropic, Google, and Meta means being first to capability frontiers matters more than cost efficiency.
So then, has the AI/ML community largely deprioritised efficiency in favour of scaling? "Yes, I think so. For LLM-focused work, that seems to be the approach. Everybody is racing to build the best model," said Achyut Tiwari, founder of Geoliquefy, a startup where AI is applied to geotechnical engineering and infrastructure resilience.
Paras Chopra, the founder of an AI research lab based in Bengaluru called Lossfunk, puts it more bluntly: "It's intelligence per unit of cost that everyone is after." But the current paradigm has inverted even that logic, scaling first and optimising later.
The Costs of Scale
The most immediate cost is environmental. Data centres consume about 1-2 per cent of global electricity; of that, AI is responsible for approximately 15 per cent. The International Energy Agency projects data centre energy demand will double by 2030.
A single GPT-3 training run consumed an estimated 1,287 megawatt-hours — enough to power 120 American homes for a year — producing roughly 552 tonnes of carbon dioxide.
"What is the biggest bottleneck to widespread AI adoption?" Vidyasagar asks rhetorically. "It's energy. These GPUs are extremely inefficient. You set up a 100,000-GPU farm, that's going to drain the local electricity. We're at the leading edge of brownouts and blackouts because of data centres."
Microsoft, Google, and Amazon have announced plans to power new data centres with nuclear energy because renewables cannot meet demand. The AI industry's trajectory is already straining electrical grids.
One might hope efficiency research could solve this. But the Jevons Paradox complicates that hope: when technology makes a resource more efficient, total consumption often increases because cheaper access enables new applications. When DeepSeek demonstrated cheaper training, the market reaction was not "great, less compute" but "great, more companies can afford large models."
The Centralisation of Intelligence
The environmental costs may not be the most consequential. The scaling paradigm also concentrates power.
Training a trillion-parameter model requires access to tens of thousands of cutting-edge GPUs, massive datasets, specialised engineering talent, and electrical infrastructure. Only a handful of organisations possess all of these.
Vaibhav Sai, the founder of a company DiagnoBac’s, which is building AI models to design better, novel biosensors, frames the stakes sharply: "If scaling continues dominating, AI becomes centralised. If efficiency breakthroughs accelerate, AI becomes decentralised." The current trajectory points towards centralisation. Compute functions as a moat.
But data access may be a deeper one. The frontier labs trained on the open internet before it closed. Stack Overflow, Reddit, and others have since restricted scraping, and legal challenges over training data are playing out in courts worldwide. The billions spent on proprietary human labelling by companies like OpenAI and Anthropic cannot easily be replicated. For latecomers, the data barrier may prove harder to cross than the compute barrier.
For India, which cannot match American or Chinese spending and faces Tier 3 chip export restrictions, this centralisation is strategically dangerous. If the only way to build competitive AI is to spend billions, India will perpetually depend on foreign models, which is to say trained on foreign data, reflecting foreign assumptions.
Vishnu Subramanian, the founder of jarvislabs.ai, building the world's most affordable and simple-to-use GPU cloud platform for accelerating AI workloads, sees both fronts clearly. "India faces a significant disadvantage on data," he argues. "Globally, access to training data has become harder — companies have changed their policies, legal battles are ongoing. We need to think creatively about generating and curating the data required for training foundational models."
The Indic languages problem is sharper still. "Why aren't models great at Indian languages? Representation. Even Hindi — India's most widely spoken language — has less than single-digit representation in internet data. And most of that is news articles, not knowledge-rich content. Until we fix this, AI models will not be great at Indic languages. We need to either increase domestic language representation on the internet or find better ways to bridge the knowledge gap between English and Chinese, which dominate, and our local languages."
The Need for Sovereign AI
The Indian government has not ignored these challenges. In March 2024, the Cabinet approved the IndiaAI Mission with Rs 10,371 crore (approximately $1.25 billion) over five years, aiming to build sovereign AI capabilities.
"We are committed to building indigenous, sovereign AI solutions to reduce dependency on foreign technology," Abhishek Singh, CEO of the IndiaAI Mission, told Inc42. "We need models trained on Indian languages, public-sector use cases, and societal contexts. Without that, AI will always remain misaligned with the people it is meant to serve," he said in conversation with the South Asian Herald.
The mission has procured over 34,000 GPUs and received over 500 proposals for foundational models. Four startups — Sarvam AI, Soket AI, Gnani AI, and Gan AI — have been selected to develop indigenous models.
Dr Vivek Raghavan, co-founder of Sarvam AI, articulates the strategic argument, as told to Business Today: "Foundational models shape language, decision-making, and whose worldview the AI reflects. India has all the ingredients to lead. What's missing is the will to align these into a national capability."
Singh has emphasised that while open-source foreign models are valuable, "countries cannot afford complete dependency on foreign systems—especially as geopolitical trust declines."
This is a coherent position. But Vidyasagar believes it conflates two different things: sovereignty and scale.


The Debate: Foundational Models vs Fine-Tuning
There is "ego," Vidyasagar argues, whenever there is excessive emphasis on building foundational models in India. "They want to say India is in an elite group of countries that developed a foundational model. I mean, who cares about that? Do you want to teach children or not?"
That is to say, the efficient use of AI to teach school children doesn’t depend on whether the AI solution uses a foundational model or a fine-tuned model.
"When you've got the objective wrong, obviously your solution is going to be wrong," he says.
His position is not that India should avoid AI development or even foundational AI development. It is that India should prioritise practical applications over prestige — and that fine-tuning open-source models is more realistic than building from scratch.
"Take these open-source models like DeepSeek or Qwen — the Chinese have been putting out really good ones. Invest in GPUs to run the model, which requires two orders of magnitude less than developing it. You don't need 100,000 GPUs to run a model."
The technical case supports him. Subramanian, who's also an AI researcher, draws a distinction that the policy debate often glosses over. "The AI we're all talking about — large language models — involves two distinct phases: pre-training and post-training. Pre-training requires massive GPU clusters and significant capital. But in recent years, reinforcement learning techniques like RLHF (reinforcement learning from human feedback) have made it possible to take a pre-trained model and fine-tune it to perform close to some of the best closed models. This is particularly valuable for enterprise use cases where data cannot leave the organisation. And importantly, this is not prohibitively expensive — it can be done for a million or two dollars."
Singh, however, has said Indian startups "will have to ultimately compete with the best in the world. It's not that all their revenues will come only from India. They will have to have a global vision... Indian startups should not get complacent just because they have government support."
This is where the tension lies. The government sees foundational models as strategic necessity. Vidyasagar sees them as distraction from immediate needs — a category error confusing prestige with purpose.
"In Davos, it was said Stanford ranks India third in AI readiness," Vidyasagar recounts. "What is AI readiness? And you don't care third in the world for what?"
India is third as an AI market, contends Dr Vidyasagar — a large consumer of AI services built elsewhere. Building use cases on foreign models creates dependency, not capability.
But does building from scratch — when open-source alternatives exist — represent the best use of limited resources?
The DeepSeek Proof
In January 2025, DeepSeek validated Vidyasagar's long-held position in a way he could not have predicted.
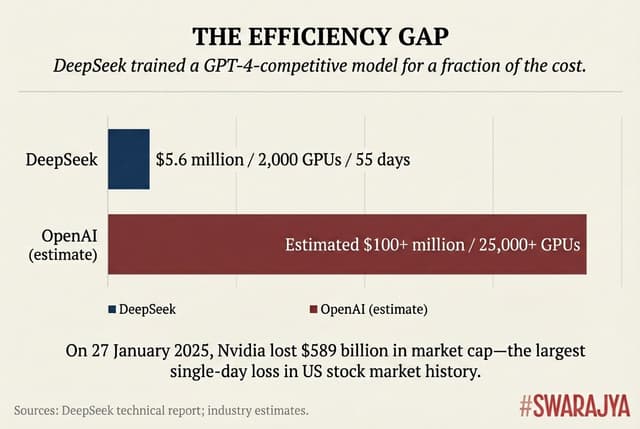
The company claimed to have trained a GPT-4-competitive model using just 2,000 GPUs over 55 days, at approximately $5.6 million — perhaps 5 per cent of what OpenAI spent. The model used what's called "Mixture of Experts" architecture, activating only relevant network portions for any query, along with aggressive optimisation techniques.
On 27 January, Nvidia lost $589 billion in market capitalisation — the largest single-day loss in US stock market history. The assumption that frontier AI required billions in infrastructure had been punctured.
Caveats apply. DeepSeek's headline figure excludes hardware acquisition and years of research investment; total expenditure likely exceeded $500 million. But even adjusted for these factors, the efficiency gains were substantial.
Crucially, constraints drove innovation. Operating under US export restrictions limiting access to advanced chips, DeepSeek had to do more with less. "Efficiency becomes a strategic weapon when compute access is constrained," as Sai put it.
India's 'Counter-Movement'
"The big labs — OpenAI, Anthropic, Google, Meta — have basically proven that scaling works," acknowledges Arsh Goyal, a senior software engineer who has worked with Samsung, the Indian Space Research Organisation (ISRO), and Codechef and is now an AI educator. "More parameters, more data, more GPUs equals better results. So the incentive structure is totally skewed towards scale. India at the same time is not in the scaling game. We don't have the capital or infrastructure to compete on raw compute."
But he sees opportunity in exactly this constraint:
"I am seeing a counter-movement happening in India: distillation techniques — taking big models and compressing them. Quantisation — running models at lower precision. Mixture of Experts architectures — only activating parts of the model. Edge AI optimisation — getting models to run on devices, not clouds. They're actually where I think India has a shot at being competitive."
These techniques map directly to efficiency research the mainstream has developed but deprioritised.
Microsoft Research, for instance, has open-sourced BitNet b1.58 — an architecture using ternary weights (-1, 0, +1) that eliminates multiplication entirely, matching full-precision performance at dramatically lower compute costs. It sits on GitHub, largely unexploited, because Redmond's infrastructure is already built for scale. India's constraints — limited chip access, smaller capital pools, data sovereignty requirements — are real. But constraints can be advantages if they force innovation in directions others are ignoring.
The same logic applies beyond training. "When you try to serve AI to a population the size of India's, entirely new challenges emerge," Subramanian notes. "There is active open-source work happening in this space, but we need to contribute meaningfully and invest in heavy R&D to solve problems unique to our scale."
Google and OpenAI have little incentive to prioritise this — their users are concentrated in developed markets with reliable connectivity and high-end devices. India's 500 million users outside the digital mainstream represent a deployment problem no Western lab has needed to solve.
The Sarvam Experiment
There is at least one Indian company proving both Vidyasagar's efficiency argument and the government's investment can work together: Sarvam AI.
Founded in July 2023 by Dr Pratyush Kumar and Dr Vivek Raghavan — both with deep roots in Indian language AI through AI4Bharat at the Indian Institute of Technology (IIT) Madras — Sarvam has focused relentlessly on Indian languages and specific use cases rather than trying to match GPT-4's general capabilities.
In April 2025, the government selected Sarvam to build India's sovereign large language model (LLM). But the company's results suggest efficiency-focused development can achieve genuine breakthroughs.
In May 2025, Sarvam released Sarvam-M, a 24-billion-parameter model showing 20 per cent improvement on Indian language benchmarks, 21.6 per cent on maths, and 86 per cent improvement on tests combining mathematics with romanised Indian languages.
In February 2026, Sarvam Vision achieved 84.3 per cent accuracy on the olmOCR-Bench benchmark, outperforming Google's Gemini 3 Pro, DeepSeek OCR, and ChatGPT, with 87.36 per cent average accuracy across 22 Indian languages.
Silicon Valley noticed. While Deedy Das, a Partner at San Fransisco-based Menlo Ventures who invests in AI startups, had been sceptical of Sarvam's direction, he publicly reversed: "I was wrong about Sarvam... They have the best text-to-speech, speech-to-text, and OCR models for Indic languages, and that's actually really valuable."
Sarvam's approach embodies a middle path. It uses government-provided compute but applies it to focused, efficiency-oriented development — not trying to build a general-purpose model competing with GPT-4 across all domains.
The Practical Alternative: 'Debias' and 'Localise'
Vidyasagar's prescription goes beyond general efficiency arguments. He has a specific proposal, and it sadly remains largely unfunded.
The core idea: start with open-source models, then adapt them through two processes he calls "debias" and "localise."
"What do I mean by debias? If you ask any question to Wikipedia or Grok, you get a very Eurocentric answer. If you ask about, say, Savarkar's role in the freedom struggle, you get a Western viewpoint, not an Indian one."
The second process, localisation, targets education specifically. Vidyasagar envisions AI tutors teaching in Indian languages at each student's individual pace and giving hints rather than just marking answers wrong.
The technical foundation is Low-Rank Adaptation (LoRA). It's a methodology that allows fine-tuning for new capabilities without degrading original performance. Fine-tune for Telugu, say, without breaking English.
The deployment model he envisions is radically decentralised: partner with non-governmental organisations (NGOs) and rural schools, refine based on feedback, release everything to the public domain for further customisation.
"Maybe we at IIT Hyderabad test with 30 schools through our Centre for Rural Education. If it works there, it'll work across Telugu-speaking states. IIT Madras does Tamil Nadu, IIT Palakkad does Kerala. The decentralisation has to be at multiple levels. The central government can't just unveil a 'national model.' That's never going to work."
The Enterprise Reality
Vidyasagar's argument finds strong support from enterprise practitioners.
Suresh Krishnan, a senior IT consultant with over 30 years across banking, insurance, and government, explains the ground reality: data sovereignty requirements effectively rule out cloud-based LLMs for most Indian enterprises. Banks and government agencies cannot let data reside on third-party models. But hosting large models in-house is prohibitively expensive — H100 GPUs cost Rs 20-25 lakh each.
"We can unlock ROI (return on investment) with smaller models. Why would I need a larger one? Enterprise use cases are specific — I want to analyse data, I need a model strong in analytics, not a huge general-purpose one. The biggest example: I don't need a train to come to Indiranagar. A two-wheeler is the most efficient way. You need the right vehicle for the right results."
Or more pithily: "Why would you shoot a cannon to kill an ant?"
"Where is value getting unlocked? In efficient models. The OpenAIs are burning billions and still not profitable — because their money comes from retail subscriptions, not enterprise. Ninety-nine percent of use cases don't need trillion-parameter models. Drug discovery might. Weather prediction might. But fit the tool to the task."
The Synthesis
The debate between Vidyasagar's efficiency-first approach and the government's sovereign-model investment is not as binary as it appears.
Sarvam's success suggests a synthesis: use government infrastructure to develop focused, efficient models optimised for Indian languages and use cases — rather than, as said before, trying to build a general-purpose model competing with GPT-4 across all domains. This captures sovereignty benefits without requiring astronomical investments.
The IndiaAI Mission's decision to support multiple smaller startups rather than one massive project reflects this logic. Subsidised GPU access at Rs 65 per hour enables experimentation without prohibitive costs.
But Vidyasagar's more radical point — skip the prestige of building from scratch and focus entirely on fine-tuning and deployment — remains largely unaddressed. His education proposal has found no significant funding.
"What I've been trying to do is raise private money — Rs 50, 60, 100 crore, which isn't much for a corporation. We could get a working prototype for AI-powered education in Indian languages. I'm trying CSR (corporate social responsibility) funding, but companies won't donate even that much."
The Big Question
The AI field's embrace of scaling over efficiency is not a conspiracy. It is the rational response to incentives rewarding benchmarks over reproducibility, prestige over purpose, capability over deployment. The Bitter Lesson taught that brute force wins; scaling laws showed progress could be bought; investment rewarded those who bought the most.
But the Bitter Lesson was a longitudinal observation — what wins in the long run with ever-increasing compute. It was never a cross-sectional claim about what to do now, with finite resources. For India, operating under financial and geopolitical constraints, it does not straightforwardly apply.
DeepSeek proved efficiency-focused innovation can close much of the gap with brute-force scaling. Sarvam proved focused development can beat general-purpose giants on specific tasks. The techniques exist. So do the use cases.
But building capability requires patience. "The example I always come back to is ISRO (the Indian Space Research Organisation)," says Subramanian. "If we hadn't invested in our space programme decades ago and instead tried to put in Rs 100,000 crore today, we still wouldn't be able to build rockets at the level we do now. It's the compounding effect of sustained investment over many years. The same principle applies here."
"We should be building foundation models, applications, new techniques that improve efficiency, and methods that help us deploy these models at scale," he argues.
"For a country as large as ours, we absolutely must. Capital is a constraint only for building foundation models. For everything else — fine-tuning, deployment research, efficiency techniques, applications — the barriers are far lower. There is no reason not to pursue all of it."
"But nobody wants to listen to that," Vidyasagar says, asking, “Do we want to teach children, or do we want to feel macho?”
The answer will determine whether India builds AI that serves its people — or merely consumes AI that serves others.
Karan Kamble writes on science and technology. He occasionally wears the hat of a video anchor for Swarajya's online video programmes.