Technology
Where Sarvam AI Stands: Not The Biggest, But Still Very Useful
Raghavan S Rao
Feb 19, 2026, 09:53 AM | Updated Feb 24, 2026, 02:54 PM IST

On 18 February 2026, in a brightly lit hall in New Delhi, a small team from a Bengaluru startup stepped onto the stage at the India AI Impact Summit and quietly changed the conversation about artificial intelligence in the world's most populous country.
They did not unveil a monster model with trillions of "brain cells". They did not promise to out-think every chatbot on the planet. Instead, they showed two carefully built AI systems designed from the ground up for Indian realities: one nimble enough to run a friendly conversation on a basic feature phone, the other powerful enough to handle serious reasoning tasks while still being far cheaper to operate than the giants from California or China.
The company is Sarvam AI. In less than three years it has gone from a promising idea to a full-stack platform that already handles text, voice, documents and on-device intelligence across most of India's 22 official languages. For ordinary Indians — the farmer in rural Odisha who prefers to speak Odia, the small-shop owner in Chennai who mixes Tamil and English, the government clerk digitising handwritten records — this matters more than any headline-grabbing number of parameters.
Sarvam is not trying to be the biggest. It is trying to be the most useful, at the lowest possible cost, under Indian control. And right now, that practical focus has put it in a surprisingly strong position.
To understand where Sarvam stands today, it helps to step back and see how far it has come, and why every step was shaped by India's unique needs.
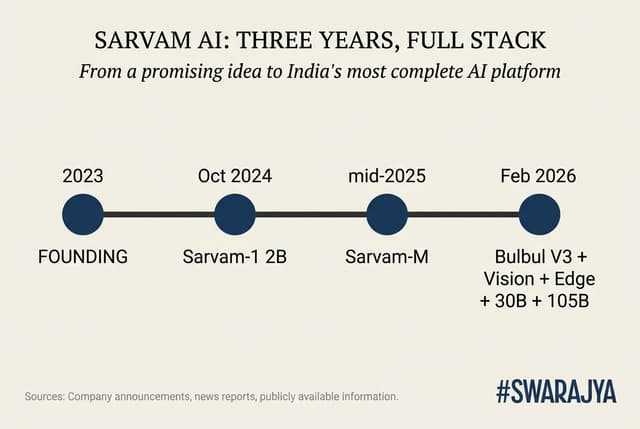
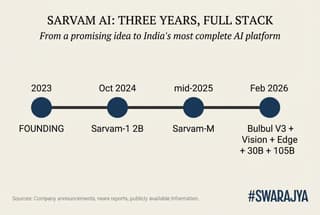
A rapid but deliberate journey
Sarvam was founded in 2023 by two experienced technologists, Pratyush Kumar and Vivek Raghavan. Their simple mission: build "sovereign" AI — technology created, trained and run in India so that Indian data stays in India and the systems actually understand Indian languages, accents, scripts and everyday life.
The first proof came quickly. In October 2024 the team released Sarvam-1, a tiny model with just 2 billion parameters (think of parameters as the adjustable connections inside the AI's "brain"). Despite its small size, it outperformed several bigger Western models on tests involving Indian languages, general knowledge and simple reasoning. It was also four to six times faster to run. That early success showed something important: when you train an AI on the right data — millions of pages of Indian news, books, conversations, code-mixed Hinglish — you do not always need to be the largest to be useful.
By mid-2025 Sarvam had scaled up. It took a respected open model from the French company Mistral, added heavy training on Indian languages, maths and programming, and released what the community quickly nicknamed "India's DeepSeek". (DeepSeek is a Chinese lab famous for squeezing remarkable performance out of smaller, cleverly designed models.) Sarvam-M, as it was called, jumped 20 per cent or more on Indian-language benchmarks and showed huge gains in maths and coding when the questions were asked in regional languages. Developers loved it because it was open and affordable.
Then the pace accelerated. In the first two weeks of February 2026 alone, Sarvam rolled out three major additions.
- Bulbul V3 is a text-to-speech system with more than 35 natural-sounding voices across 11 Indian languages, soon expanding to 22. It handles mixed languages, numbers, technical terms and emotional tone so well that listeners in blind tests preferred it over several global rivals, especially for phone-quality audio.
- Sarvam Vision is a specialised 'eyes' model that reads documents, tables, handwritten notes and complex layouts in Indian scripts; on standard tests it beat Google's latest systems and others by clear margins, especially in low-resource languages such as Santhali or Kashmiri.
- Sarvam Edge is a suite of models small enough to run directly on phones or simple devices without needing the internet — crucial in areas where mobile data is expensive or patchy.
All of this was warm-up for the main event on 18 February.


The latest releases, explained simply
Sarvam unveiled two new large language models — the core "thinking" engines — plus the supporting voice and vision pieces that turn them into complete tools.
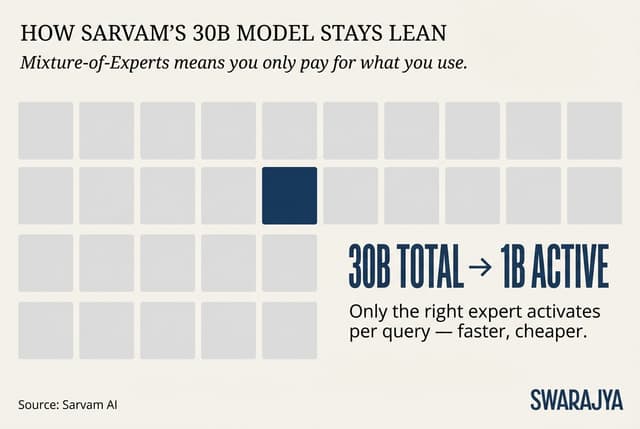
The smaller one is called Sarvam-30B. It has 30 billion parameters in total, but thanks to a clever design called mixture-of-experts (MoE), it only "wakes up" about 1 billion of them for any single answer. Imagine a huge office building with hundreds of experts on different floors; instead of turning on all the lights and air-conditioning for the whole building every time someone asks a question, you just switch on the lights in the one room that has the right expert. This makes the model much cheaper and faster to run.
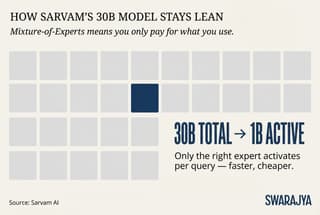
It is optimised for live conversation. It can remember up to 32,000 "tokens" (roughly 24,000 words) of earlier chat — enough for long back-and-forth discussions. In demonstrations it powered a chatbot named Vikram (after the Indian space pioneer Vikram Sarabhai) that switched effortlessly between Hindi, Punjabi, Tamil and English, even on a basic feature phone. That is revolutionary in a country where hundreds of millions still use simple phones and prefer speaking over typing.
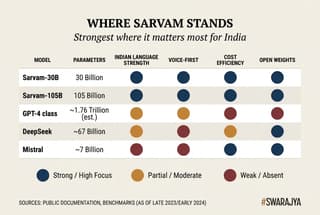
The bigger sibling is Sarvam-105B. It has 105 billion parameters and a much larger memory of 128,000 tokens. It is built for harder jobs: solving complex maths or logic problems, writing detailed reports, or acting as an intelligent assistant that can plan several steps ahead. Sarvam says it matches or beats far larger models on tests that matter to Indians — technical questions in regional languages, reasoning that mixes English and local terms, and practical tasks such as helping with government forms or business documents.
Both models were trained from scratch on trillions of tokens heavily weighted towards Indian content. They are not just copies of foreign systems with Indian words sprinkled on top; the cultural understanding is baked in from the beginning.
Help from friends, but on Indian terms
None of this happened in isolation. Sarvam received computing power through the government's IndiaAI Mission, which is deliberately building domestic AI infrastructure. Training ran on clusters provided by Yotta, one of India's big data-centre companies. For the crucial job of making the models fast and cheap to use (what engineers call "inference"), Sarvam worked closely with Nvidia. Joint teams optimised the software so that on Nvidia's latest Blackwell chips the 30B model runs four times faster than on older hardware, while keeping response times quick enough for natural conversation. The result is that these Indian models can deliver high performance without needing an army of the most expensive GPUs.
This is not "dependence". It is smart partnership. Sarvam keeps full control of its data and models; Nvidia supplies the best engine-tuning expertise. The same pattern appears with hardware partners such as Qualcomm for phones and HMD Global (Nokia) for feature phones.
Where Sarvam actually stands today
So how good are these models, really, in the wider world of AI? Let us be clear and optimistic at the same time. Sarvam is not yet competing head-to-head with the absolute cutting-edge closed models from OpenAI or Anthropic on every possible English-language task. Those systems are still larger, trained on vastly more global data, and excel at ultra-specialised or highly creative work in pure English. If you want an AI to write a 50-page legal brief in flawless international English or solve the hardest university-level physics problems in one shot, the American frontier models probably still have an edge today.
But that is not the race Sarvam is running.
In the areas that matter most to India — and to hundreds of millions of people across the global south — Sarvam is already among the best, and in many cases the best. Its models understand code-mixed language naturally. They read messy handwritten forms in Devanagari or Tamil script with impressive accuracy. They speak with natural rhythm and emotion in regional voices. They run efficiently enough that a bank in a small town can afford to give every customer a voice assistant, or a state government can digitise millions of records without huge cloud bills.
Cost is the silent killer in AI. Running a big model can be expensive. Because Sarvam's 30B model activates only a fraction of its parameters, and because of the Nvidia optimisations, the company can offer pricing that makes widespread use realistic. A voice-based government helpline that costs pennies per conversation instead of dollars changes everything for public services.
The open approach helps too. Sarvam plans to release the model weights openly — developers can download and adapt them — even if the exact training recipes stay proprietary for now. That mirrors what Mistral and early DeepSeek did: give the community something powerful to build on, while protecting the secret sauce of data. Already, Indian developers are experimenting with fine-tuned versions for law, medicine, agriculture and education.
Critics might say Sarvam is "only" strong in its home market. That misses the point. India is not a small niche. With 1.45 billion people, 22 scheduled languages, and a massive digital-economy push (UPI, Aadhaar, Digital India), the Indian market is one of the most important testing grounds for truly inclusive AI. What works here at scale will be valuable everywhere languages and voice matter more than English text.
In global rankings of "overall smartest model", Sarvam sits comfortably in the strong second tier — impressive for a company that is barely three years old and operating with a fraction of the resources of the American or Chinese leaders. In the specific category of "most useful AI for multilingual, voice-first, cost-sensitive emerging markets", it is already a leader.
The road ahead
Sarvam's leaders are realistic. Co-founder Pratyush Kumar has said the 105B model was chosen because it matches real-world needs, not because bigger is always better, and that performance will keep improving with more targeted training. The company is building tools on top: Sarvam Studio for translating and dubbing content, agent platforms for automated workflows, enterprise versions for banks and governments.
Challenges remain. Compute is still expensive, even with government help. Talent wars with global tech giants are real. Turning impressive demos into reliable systems used by hundreds of millions of ordinary citizens will require enormous work on infrastructure, regulation and last-mile adoption.
Yet the momentum is unmistakable. In three short years Sarvam has built a complete Indian AI stack: understanding, speaking, seeing, running on cheap devices, all optimised for Indian languages and costs. It has done so while staying open, partnering with government without losing independence, and focusing relentlessly on practical delivery rather than headline size.


For a country that once worried it would always be a consumer of foreign technology, this is a genuine turning point. Sarvam is showing that India can move from being a world-class software-services nation to a world-class AI-innovation nation — not by copying the West or China, but by solving its own problems in its own way.
If the next few years bring continued steady progress — deeper multimodality, even better efficiency, and a thriving ecosystem of apps and services built on these models — Sarvam could do for AI what the Indian IT industry did for software services two decades ago: turn apparent constraints (diverse languages, price sensitivity, late start) into a distinctive global strength.
The models announced this week are not the finish line. They are the clearest sign yet that India is no longer just watching the AI race from the sidelines. It is running its own smart, efficient, inclusive leg of the race — and the rest of the world would be wise to watch closely. Because when AI finally reaches the next billion users, a large share of them will very likely be speaking to a Sarvam-powered assistant in their own language, on their own terms.
A public policy consultant and student of economics.