Technology
Is Sarvam A DeepSeek Clone? Yes And No!
Raghavan S Rao
Mar 07, 2026, 08:05 PM | Updated 08:09 PM IST

When Sarvam AI unveiled its new language model at India's AI Impact Summit in New Delhi in February 2026, the Bengaluru-based startup had reason to feel confident. The model, called Sarvam-105B, had been trained from scratch on Indian soil using thousands of Nvidia graphics processors. It could reason in Sanskrit, parse legal documents in Tamil, and switch between Hindi and English mid-sentence — the way hundreds of millions of Indians actually speak.
On certain mathematical reasoning benchmarks, it matched or outperformed DeepSeek-R1, a Chinese model more than six times its size. Prime Minister Narendra Modi was photographed wearing the company's prototype AI-powered smart glasses at the event.
The backlash arrived within hours. On X, formerly Twitter, critics dissected the model's configuration file and declared Sarvam-105B a "scaled-down DeepSeek architecture clone." One widely shared post ran the file through ChatGPT, which described it as a "Mini DeepSeek-V2 style model."
The implication was damning: that Sarvam had simply copied China's homework and slapped an Indian flag on it. The accusation stung because it was not the first time the company had faced questions about originality — an earlier model built on top of a French startup's technology had drawn similar criticism.
The charge was not entirely baseless.
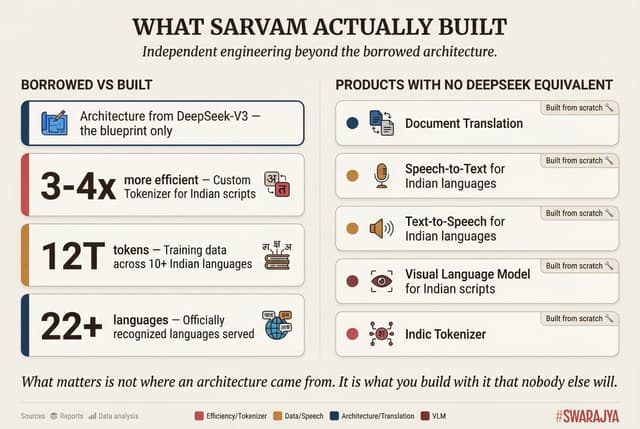
Sarvam has openly acknowledged that its architecture draws on DeepSeek-V3, particularly a technique called multi-head latent attention that compresses data to reduce memory costs, and a design known as Mixture of Experts that activates only a fraction of the model's capacity for each query. Nvidia's own technical blog confirmed the lineage. The architectural similarities are real.
But the conclusion drawn from those similarities — that Sarvam is merely a copycat — gets the story of artificial intelligence exactly backwards. It misunderstands what an "architecture" is, what Sarvam actually built, and, most fundamentally, how every significant advance in this field has worked for the past eight decades.
To understand why the criticism is misplaced, it helps to know what building a language model actually involves.
An architecture is a blueprint — a set of design decisions about how to wire a neural network, how information flows through it, and how different components interact. It is published in academic papers precisely so that others can use it. The model itself — the thing that actually understands language — is something else entirely. It is the product of training data, engineering decisions, and months of computation.
Using the same architecture as someone else is like building a house from the same floor plan: the structure may be similar, but the bricks, the wiring, the plumbing, and the furniture are all your own.
What Sarvam built independently is substantial. The company developed a custom tokeniser — the component that breaks text into pieces the model can process — specifically designed for Indian scripts. Standard multilingual models require four to eight tokens to represent a single word in languages like Hindi or Bengali. Sarvam's tokeniser does it in roughly one and a half to two tokens, making the model three to four times more efficient for Indian languages.
For a country where, as co-founder Vivek Raghavan has put it, "the way people speak changes every 50 kilometres," this is not a marginal improvement. It is the difference between AI that is economically viable for a billion people and AI that is not.
The training data pipeline was equally original. The company curated some twelve trillion tokens of text spanning computer code, web content, mathematics, and more than ten Indian languages, including what it describes as low-resource languages — Kashmiri, Dogri, Konkani — for which training data barely exists. It built custom tools for scoring data quality, developed its own reinforcement learning infrastructure, and ran the entire training process on more than four thousand Nvidia H100 processors. Sarvam's CEO, Pratyush Kumar, posted on X that his team "admire the Deepseek team and follow and learn from their research," before noting that the 105B model achieved its results "with a small team and with a smaller model size." A Sarvam engineer was more emphatic: all the company's models, he wrote, are "foundational and trained from scratch."
Beyond the headline model, Sarvam has built products that have no DeepSeek equivalent at all: a document translation system, speech-to-text and text-to-speech engines for Indian languages, and a visual document reader for Indic scripts. The accusation of cloning does not account for any of this.

The deeper problem with the "copycat" charge is that it could be levelled at every major AI system ever built — including DeepSeek itself. The history of artificial intelligence is an unbroken chain of researchers building on the work of those who came before. Each link is a story of someone reading a paper, seeing what it made possible, and pushing the idea further.
The chain begins in 1943, when a neurophysiologist named Warren McCulloch and a self-taught teenage logician named Walter Pitts published the first mathematical model of a neural network. Their model could compute logical functions but had no ability to learn. In 1958, a psychologist at Cornell named Frank Rosenblatt added learnable weights — drawing explicitly on McCulloch and Pitts, and on the neuropsychologist Donald Hebb's theory about how brain cells strengthen their connections — and created the Perceptron, the first trainable neural network. He built a physical machine with four hundred light sensors and motors that adjusted weights automatically.
Then progress stalled. In 1969, two MIT professors published a book proving that single-layer networks could not solve even elementary problems. Funding dried up for more than a decade. The thaw came through a technique called backpropagation — essentially, a way to tell each part of a large network how to adjust itself to reduce errors. But even this supposed breakthrough had been invented multiple times: by a Finnish master's student in 1970, by an American PhD candidate in 1974, and by Yann LeCun in France in 1985, before David Rumelhart, Geoffrey Hinton, and Ronald Williams published a celebrated version in the journal Nature in 1986 that reignited the field. Hinton later admitted he had no idea someone else had already done similar work.
The pattern continued. In 1997, two German-speaking researchers, Sepp Hochreiter and Jürgen Schmidhuber, published a paper on Long Short-Term Memory networks that solved a fundamental problem with training deep networks — building on backpropagation, which built on the Perceptron, which built on McCulloch and Pitts. In 2013, a team at Google led by Tomas Mikolov showed that computers could represent words as mathematical vectors, capturing meaning in a way that made "king minus man plus woman equals queen" a computable statement. But the underlying idea — that words derive meaning from the company they keep — had been articulated by a linguist named J.R. Firth in 1957.
The most consequential paper in modern AI arrived on June 12, 2017, when eight researchers at Google published "Attention Is All You Need." The paper proposed the Transformer, an architecture that dispensed with older techniques entirely and relied on a mechanism called attention — the ability of a model to focus on the most relevant parts of its input when producing each piece of output. The title was a nod to The Beatles. The name "Transformer" was chosen because one of the authors simply liked the sound of the word.
But the Transformer did not materialise from thin air. Its central mechanism had been introduced three years earlier by researchers in Montreal who were working on machine translation. Self-attention, in various forms, had appeared in several prior papers. One of the Transformer's own co-authors had published work the previous year showing that attention without older sequential techniques might be sufficient for language tasks — and it was that earlier result that gave him "the suspicion that attention without recurrence would be sufficient for language translation." The Transformer's genius lay not in inventing new components but in combining existing ideas with extraordinary engineering taste.
Google published the paper openly and never patented the architecture. The reason was partly cultural: the company maintained a scholarly ethos essential for recruiting top researchers. As one observer noted, it is debatable whether Google could ever have attracted the talent that produced the paper without that openness. The consequence is that every major AI model since — OpenAI's GPT series, Google's own Gemini, Meta's LLaMA, Anthropic's Claude, DeepSeek, Sarvam — rests on an architecture that Google gave away for free. The paper has been cited nearly two hundred thousand times. All eight of its original authors eventually left Google; seven founded their own AI companies.
This brings us to DeepSeek, the company Sarvam is accused of copying. DeepSeek was founded in July 2023 by Liang Wenfeng, a Chinese quantitative hedge fund manager who had quietly stockpiled thousands of Nvidia processors before American export restrictions took effect. It operates out of Hangzhou with roughly 150 to 200 researchers, many of them recent university graduates.
Every component of DeepSeek's architecture traces to prior published work. The Transformer foundation comes from Google. The Mixture of Experts concept — the idea of having many specialist sub-networks with a gating mechanism that routes each query to the most relevant ones — originates in a 1991 paper by Robert Jacobs, Michael Jordan, Steven Nowlan, and Geoffrey Hinton. Think of it as a hospital with dozens of specialist doctors and a triage nurse who decides which ones each patient needs to see. Google scaled this idea for language models in 2017 and simplified it further with the Switch Transformer in 2021. DeepSeek's refinements are genuine — finer-grained specialisation, clever compression tricks, a training method that lets reasoning emerge without human-written examples — but they are refinements of ideas that are, in some cases, thirty-five years old. DeepSeek's own technical reports contain hundreds of citations to Google, Meta, OpenAI, and academic researchers.
When DeepSeek-R1 topped the American iOS App Store in January 2025, Nvidia lost $589 billion in market value in a single day. Marc Andreessen called it "AI's Sputnik moment." Nobody accused DeepSeek of merely copying Google's Transformer or OpenAI's reasoning paradigm. The achievement was recognised as innovation built on shared knowledge. The question is why Sarvam's similar act of building on DeepSeek's published research provoked a different reaction.


The pattern of innovation through inheritance extends far beyond AI. In 1991, a Finnish student named Linus Torvalds announced he was building a free operating system, inspired by Unix and a teaching system called Minix. He wrote every line of code himself but was explicit about the intellectual debt. That project — Linux — now powers every one of the world's five hundred fastest supercomputers and more than three billion Android devices. The web browser you are likely reading this on descends from KHTML, a modest rendering engine built by open-source volunteers for a Linux desktop in 1998. Apple forked it to create Safari's engine. Google used that to build Chrome, then forked it again. Browsers in that lineage now account for more than ninety per cent of global web usage.
A public policy consultant and student of economics.